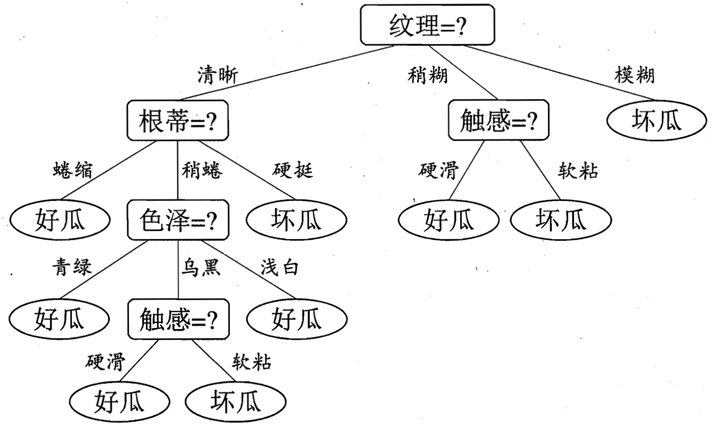
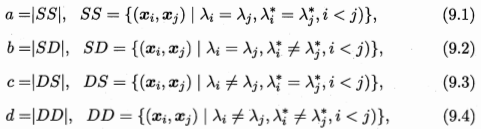语法分析
语法(syntax):组合token以形成phrases,clauses和sentences
对于某些式子的表示,比如带有嵌套深度比较大的括号时,有限自动机并不能识别出括号配对的情况,这是因为状态数为N的有限自动机无法记忆嵌套深度大于N的括号。
上下文无关文法
上下文无关文法就是说这个文法中所有的产生式左边只有一个非终结符,例如:
1 | S->aSb |
这个文法的两个production的左边都只有一个非终结符,那么只需要找到符合production右边的字符串,就可以对其进行规约。
然而
1 | aSb->aaSbb |
这就是上下文相关文法,因为第一个production的左边不止一个终结符,所以在匹配的时候必须要确保S有正确的“上下文”。
推导
为了证明某个文法的类型,我们必须要进行推导(derivation),即从开始符号出发,对其右部的每一个非终止符,用该非终止符production的任一个右部替代它。
- 最左推导:总是扩展最左边的非终止符;
- 最右推导:总是扩展最右边的非终止符;
语法分析树
parse tree就是将一个推导中的各个符号连接到从它推导出来的符号而形成的。不同的推导可以得到相同的parse tree。
二义性文法
如果一个文法能够推导出两颗不同的parse tree,则认为该文法具有二义性。这种情况下,编译器就无法利用parse tree去解析语义。以下就是一个二义性文法的例子:

但是二义性的文法是可以通过某些转换来消除,一般来说引入一些新的非终止符,来提高某些表达式的优先级。
文件结束符
语法分析器会读入文件结束符号,一般来说我们使用$符号表示文件的结束。
预测分析
使用一种叫做梯度下降(recursive descent)的简单算法可以对grammar进行分析,它只适用于每个子表达式的第一个终结符号能够为production提供足够的信息的情况。其中每个非终结符对应的,都有一个函数。
FIRST集合和FOLLOW集合
FIRST(S)是从S可以推导出的任意字符串中的开头终结符组成的集合,因此如果两个production有着相同的左部符号,但它们的右部有着重叠的FIRST集合,那么该文法不能使用预测分析。
能产生空字符串的符号,称呼为nullable。
记住下列结论:
- 若X可以推导出空字符串,那么nullable(X)为真;
- FIRST(S)是从S可以推导出的任意字符串中的开头终结符组成的集合;
- FOLLOW(X)是可以直接跟随于X之后的终结符集合;
构造一个预测分析器
由于非终结符X的分析函数对X的每个产生式都有一个子句,因此该函数必须根据下一个输入来选择其中的一个子句。我们需要的所有信息可以用一个二维表来表示,该表以文法的非终结符X和终结符T作为索引。
对于每个属于FIRST(X)的T,在表的X行T列填入该production X->y;如果y为nullable,那么对于每个属于FOLLOW(X)的T,在表的X行T列填入该production X->y。

像上图这种情况,一个表项里有多个表达式,就会产生二义性的文法。若一个文法的预测分析表不含有多重定义的项,则称为LL(1)文法。
LL(1): Left to right parse; Leftmost derivation; 1-symbol lookhead
消除左递归
看这样的文法:
1 | E->E+T |
在这种情况下,将会导致LL(1)的分析表中出现了双重定义的登记项,因此任何属于FIRST(T)的tokens必然属于FIRST(E+T),这就是左递归。
为了消除左递归,我们可以这样重写:
1 | E->TE' |
LR分析
LL(k)的一个弱点就是,在我们仅仅看到右边的k个tokens时就需要做出预测。相比而言,LR(k)分析是一种更好的选择。
LR(k): Left to right parse; Rightmost derivation; k-token lookhead
来看一个典型的例子:

- shift:将第一个token压进栈;
- reduce:选择文法规则:X->ABC,依次将C,B,A从栈中弹出来,将X压进栈;
LR分析引擎
LR分析器是通过DFA作用于栈,来实现reduce和shift操作的。转换操作主要有以下4种:
- sn: shift into state n
- gn: goto state n
- rk: reduce by rule k
- a: accept
LR(0)分析器
LR(0)是一种只需要分析查看栈就可以进行分析的文法,它的shift、reduce操作不需要进行任何超前判断
SLR分析器
如果用LR(0)去构造分析表:

在状态3的时候,遇到符号+,就会出现多重定义的项,分析器既需要shift到状态4,也需要对production2进行reduce。这是一个reduce-shift冲突。
因此我们可以构造SLR分析器来解决这个问题。
SLR的构造与LR(0)基本一样,除了它只在FOLLOW集指定的地方放置规约操作。
LR(1)项和LR(1)分析表
之所以使用LR(1),是因为即便使用了SLR(0),还是不能完美地解决所有的冲突。考虑αF.β,我们知道,F的follow集合包含字符串β的first集合。因此我们在SLR(0)中使用的follow集合不一定能正确的预测出产生式。
因此,我们重新定义了项,它包含产生式,标记状态的点,超前查看符号集合。
我们可以使用下面的算法计算一个状态中每一项的具体内容:


LALR(1)分析表
由于LR(1)的状态可能太多了,因此我们可以合并那些除了超前查看的符号集合外都相同的两个状态。